BitMap 及其在 ClickHouse 中的应用
BitMap
问题要从面试或者大数据场景下最常见的一个算法说起,问题是这样的,假如有几十亿个 unsigned int 类型的数据,要求去重或者计算总共有多少不重复的数据?最简单的办法就是直接利用一个 HashMap,进行去重。但是这里面有个内存使用量的问题,几十亿个元素,即使不考虑 HashMap 本身实现所用到的数据结果,单单 key 本身,假如每个 unsigned int 占用 4 个字节,简单算一下的话,这里都需要几十 GB 的内存占用,因此,这里就引出了 BItMap。
BItMap 的思想非常简单,就是用一个 bit 表示一个二元的状态,比如有或者没有,存在或者不存在,用 bit 本身的位置信息,对应不同的数据。比如针对上面的问题,我们可以开辟一个 2^32 bit 的内存空间,每一个 bit 存储一个 unsigned int 类型的数据,有就是 1,没有就是 0,总共需要存储 unsigned int 类型的最大范围个数据,也就是 2^32 个数据,这个 2^32 其实就是所谓的基数。如下图所示:
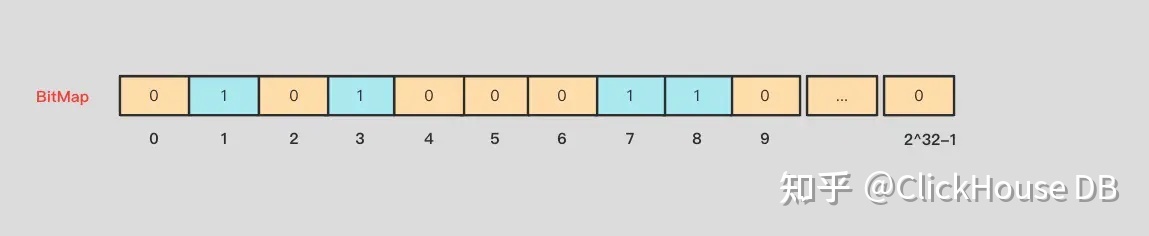
假如存在数字 8,那就把对应的第 8 位的值赋为 1。上图插入的数据为 1、3、7、8。接着依次把所有的数据遍历然后更新这个 BitMap。这样我们就可以得到最终结果。
Bloom Filter
假如上面的问题变成了对几十亿个 URL 做判断,那应该怎么去做呢?URL 没有办法和 BitMap 的位置关系对应上,所以,我们需要加一层哈希,把每个 URL 经过哈希运算得到一个整数,然后对应上 BitMap。如下图所示:
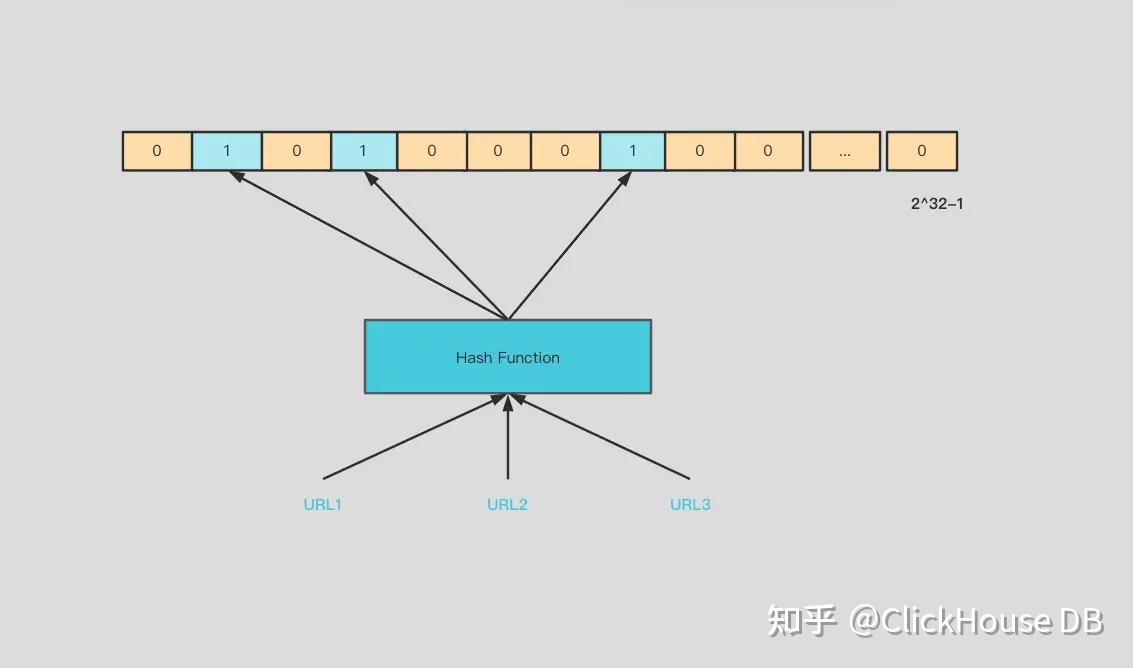
但是有哈希,肯定会存在碰撞,如果 BitMap 基数(也就是长度)比较小,那碰撞的概率就大,如果基数比较大,那占用的空间又会比较多。Bloom Filter 的思想就是引入多个哈希函数来解决冲突的问题。也就是说对每个 URL,经过多个哈希函数的运算,得到多个值,每个数值对应的 BitMap 的对应的位置都赋值为 1。这个两个 URL 经过多个哈希函数结果还是一样的概率就大大降低。
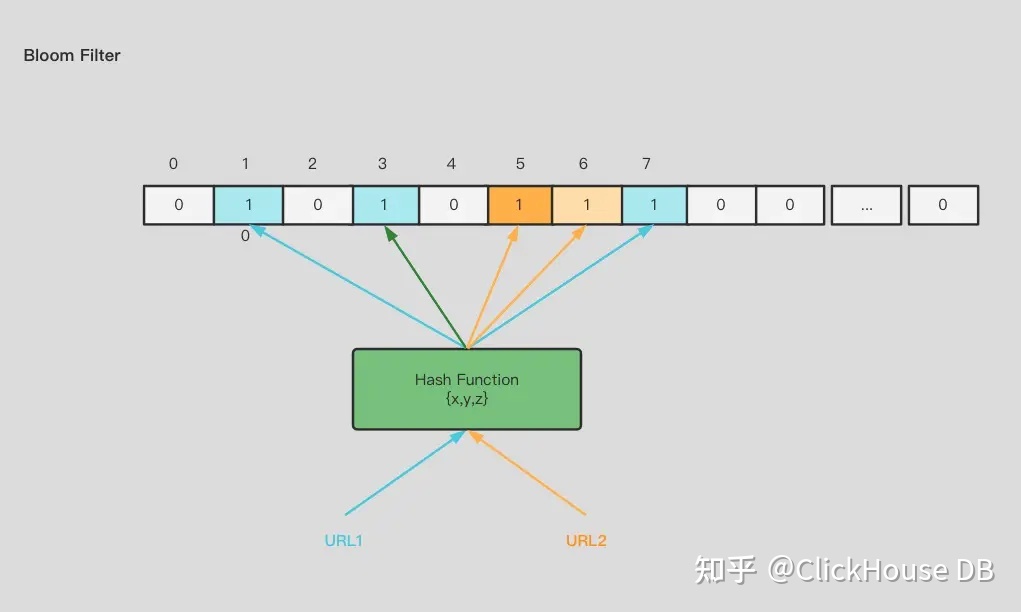
但是由于依然存在冲突的可能性(其实冲突就是来源于我们 BitMap 的长度小于了数据量的基数,这也就是牺牲了准确性换来了空间使用的减少),所以 Bloom Filter 存在假阳性的概率,不适用于任何要求 100% 准确率的场景,也就是说 Bloom Filter 只能用来判无,不能用来判有。比如一个 URL 经过多次哈希运算之后,发现对应的 BitMap 的位置都已经是 1 了,那也不能说明,这个 URL 之前存在过了,也有可能是哈希冲突的结果。但是一个 URL 经过多次哈希运算之后,发现对应的 BitMap 的位置不是都是 1,那当前 URL 之前一定是没有存在过的。
可以看到,Bloom Filter 引入多次哈希,在查询效率和插入效率不变的情况下,用较少空间的 BitMap 解决大数据量的判断问题。
RoaringBitMap
大部分情况下仅仅做有无的判断是不能满足使用需求的,我们还是需要真正意义上的 BitMap(可以方便的用来做交并等计算),但是最好可以在基数比较大的时候,依然可以占用相对比较小的空间。这就是 RoaringBitMap 所要实现的。
简单来说 RoaringBitMap 是 BitMap 的一种带索引的复杂 BitMap 数据结构。以 32 位的 RoaringBitMap 为例,首先划分 2^16 个空间(Container),每个 Container 内部都是一个大小为 2^16 bit 的 BitMap,总的内存使用量还是 2^32 = 512Mb。这样的话和普通的 BitMap 是没有区别的,而 RoaringBitMap 的创新之处在于每个 Container 内的 BitMap 是在没有使用到的情况下是可以不分配内存空间的。这样可以大大减小内存的使用量。
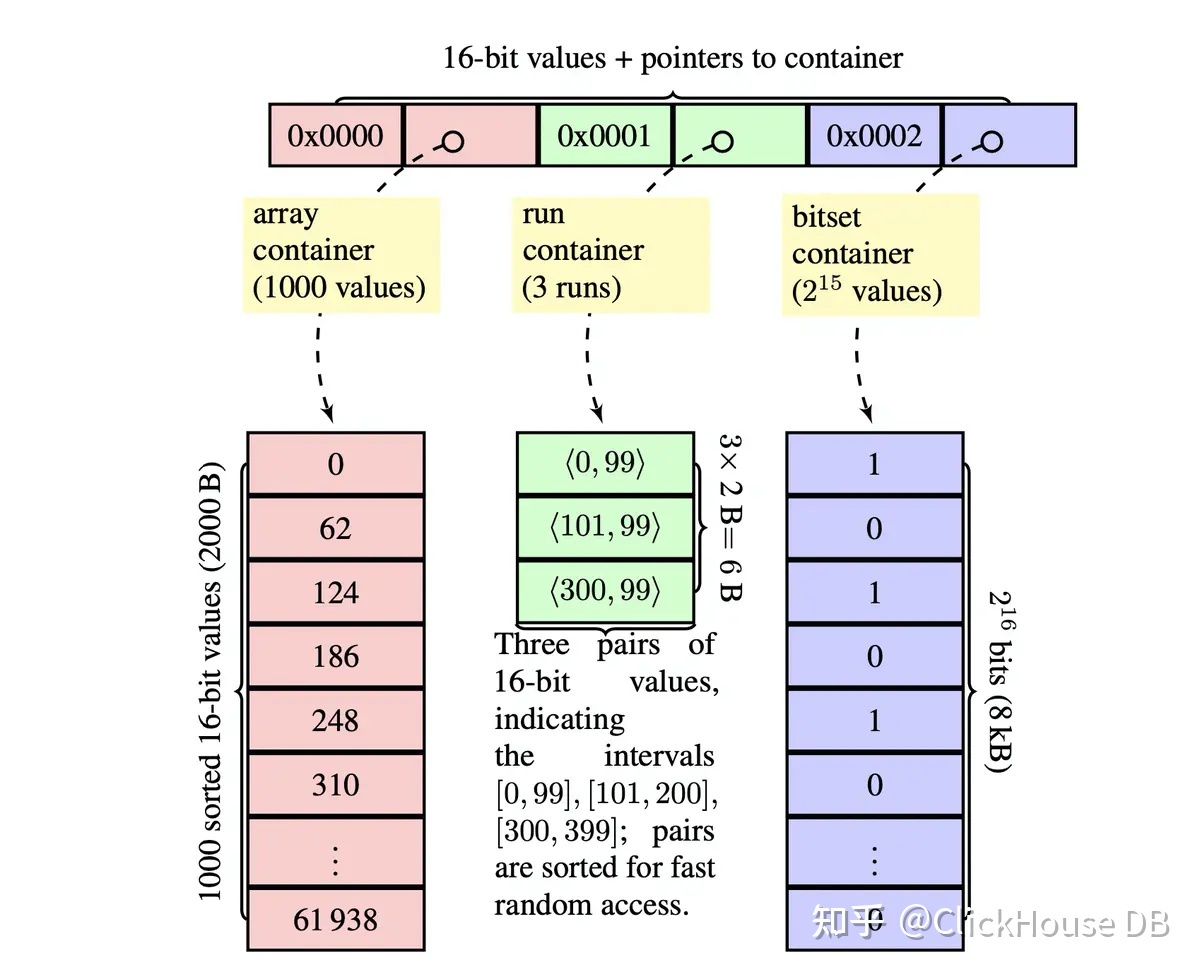
(这张图片是 Roaring Bitmaps: Implementation of an Optimized Software Library 论文原图)
要将一个 4 个字节的数据插入 RoaringBitMap,首先要用数据的高 16 位,找到对应的 Container,然后用数据的低 16 在 Container 中插入。
在每个 Container 内部,RoaringBitMap 不是简单的用 BitMap 来进行数据的存储,而是把 Container 的类型划分为几种,不同的 Container 用来存储不同情况的数据。
array container
当 2 个字节(4 个字节的原数据,低 16 位用来插入具体的 Container 中)的数据,总的个数小于 4096 个的时候,当前 Container 使用 array Container。为什么是 4096 个呢?4096*2B=8Kb,而一个 Container 如果是 bitmap 的结构的话,最多也就是 2^16bit=8Kb 的空间。所以这里当数据个数小于 4096 使用 array Container 会更节省空间。当然这里名字为 array Container,实际上是链表结构,不需要最开始就初始化 4096 个 short int 的数组。
bitmap container
当 array Container 存储的数到 4096 个的时候(也就是使用内存到 8Kb 的时候),array Container 会转换为 bitmap container,bitmap container 就是一个 2^16 bit 普通的 bitmap,可以存储 2^16 = 65536 个数据。这个 8Kb 还有一个好处,是可以放到 L1 Cache 中,加快计算。
run container
这个严格的说,只是一种数据压缩存储方法的实现。其压缩原理是对于连续的数字只记录初始数字以及连续的长度,比如有一串数字 12,13,14,15,16 那么经过压缩后便只剩下 12,5。从压缩原理我们也可以看出,这种算法对于数据的紧凑程度非常敏感,连续程度越高压缩率也越高。当然也可以实现其他的压缩方法。
RoaringBitMap 其核心就在于加了一层索引,利用复杂的数据结构换取了空间上的效率。需要注意的是这里并没有增加计算的复杂度,其出色的数据结构让其在做交并计算的时候性能也毫不逊色。
ClickHouse 中的实现和使用
ClickHouse 中有 bloom_filter 类型的 Skipping indexs,可以方便的用来过滤数据。
ClickHouse 实现了大量的 BitMap 的函数,用来操作 BitMap。ClickHouse 中的 BitMap 在 32 位的时候用的是 Set 实现的,大于 32 位的时候也是使用 RoaringBitMap 实现的。我们这里不看具体的函数,我们来看一个典型的使用场景。
最常见的一个场景是根据标签来进行用户的圈选。常见的解决办法是有一张用户标签表,比如
CREATE TABLE users_table
(
uid UInt64,
tag1 String,
tag2 String
)
ENGINE = MergeTree
ORDER BY uid;
要查询标签 tag1='xx'和 tag2='xx'的用户需要执行 SQL:
SELECT uid FROM users_table WHERE tag1='xx' AND tag2='xx'
但是由于不可能对每个 tag 列构建一级索引,所以这条 SQL 执行的效率并不高。可选的一种方式是先构建关于标签的 BitMap 数据结果,然后进行查询:
(1) 创建 tag 的 bitmap 表:
CREATE TABLE tag_users
(
tag_id String,
users AggregateFunction(groupBitmap, UInt64)
)
ENGINE = MergeTree
PARTITION by tag_id
ORDER BY tag_id;
(2)写入数据
insert into tag_users select tag1,groupBitmapState(uid) from users_table group by tag1;
(3)查询
SELECT bitmapToArray(groupBitmapOrState(users)) FROM tag_users WHERE tag_id = 'xx';
如果有多张 tag 表,进行交并计算(要比普通的用户表进行 JOIN 或者 IN 计算要高效很多):
with
(
SELECT groupBitmapOrState(users) FROM tag_users WHERE tag_id = 'f'
) as user_group1,
(
SELECT groupBitmapOrState(users) FROM tag_users2 WHERE tag_id = 'ff'
) as user_group2
select bitmapToArray(bitmapAnd(user_group1, user_group2));